Hey there, awesome coder! If you’ve ever wanted to build a Broken Link Checker to keep your website spick and span, you’re in the perfect spot. We’re going to code a super useful Python script. This tool will automatically scan your site for dead ends and broken links. It’s a fantastic way to improve your site’s health and user experience!
No more manual clicking through every single link. We’ll build something cool and practical together. Get ready to make your website more robust!
What Exactly Are We Building?
We’re building a Python script that acts like a digital detective. It will visit a website, find all the links on a page, and then check each one. We want to know if these links actually work. A broken link leads to frustration and a bad user experience. Plus, search engines don’t like them either!
This script will report which links are healthy and which are broken. It’s like having a personal SEO assistant. Imagine the time you’ll save! This project will teach you about web scraping basics and HTTP requests. You’ll gain valuable skills for many web development tasks.
Your Python Script for a Supercharged Broken Link Checker
Let’s dive right into the code that makes all this magic happen. This Python script uses a few powerful libraries. We will walk through each part shortly. Don’t worry if it looks like a lot at first glance. We’ll break it down piece by piece. You’ll understand every line.
Here’s the core of our Broken Link Checker:
[INJECT_PYTHON_CODE]
Breaking Down the Broken Link Checker Magic
Now that you’ve seen the full script, let’s explore how it actually works. We’ll go through it step by step. Each part plays an important role in finding those pesky broken links. Understanding each section will help you customize it later. It’s all about making the code work for you.
Setting Up Your Environment and Imports
First, we need to gather our tools. We import libraries like requests and BeautifulSoup. The requests library helps us fetch web pages from the internet. It makes HTTP requests super easy. BeautifulSoup, often called ‘bs4’, helps us parse HTML content. It’s excellent for finding specific elements, like links! We also bring in urllib.parse to handle URLs properly. This ensures our links are always correct and valid.
Pro Tip: Always start by understanding your imports! They tell you what external powers your script is tapping into. It’s like checking your toolbox before starting a DIY project.
Grabbing Web Page Content
Our script needs to ‘visit’ a webpage first. We use requests.get(url) for this. This line sends a request to the target website. If successful, it brings back the HTML content of that page. Think of it as opening a web page in your browser programmatically. We check if the response status code is 200. A 200 status means the page loaded successfully. Any other code might mean trouble. This initial check is crucial for our Python SEO Audit tool.
Finding All the Links
Once we have the page’s HTML, BeautifulSoup takes over. We create a BeautifulSoup object from the HTML content. Then, we use soup.find_all('a', href=True). This command searches for all <a> tags. These are the anchor tags that contain links. The href=True part makes sure we only get tags that actually have an href attribute. These attributes hold the link destinations. We extract these href values for later checking.
It’s like sifting through a document for every highlighted piece of text. BeautifulSoup makes this task incredibly simple and efficient. Learning this technique opens doors to many web scraping possibilities. You can extract almost any data from web pages.
Testing Each Link’s Health
This is where the ‘broken link checker’ part truly shines. For each link we found, we send another requests.get(). This time, we are checking the link itself. We use a try-except block. This handles any network errors gracefully. If a link doesn’t respond, it’s definitely broken. We also check the HTTP status code. A 200 is good, meaning the link works. Other codes like 404 (Not Found) or 500 (Server Error) mean the link is broken. This method ensures robust checking.
Remember: Testing links one by one can be time-consuming for very large sites. Consider adding delays to avoid overwhelming servers! Be a good internet citizen.
Presenting Your Findings
Finally, we print out the results. Our script tells us which links are good and which are broken. It also shows the status code for each link. This clear output helps you pinpoint exactly what needs fixing. We store these results in lists, then display them neatly. This reporting makes the script incredibly useful. You’ll quickly see the health of your website’s navigation. This function demonstrates clear Python Functions Explained.
You can easily extend this to save to a file or even send an email. Imagine getting an automated report daily! This level of automation is what Python excels at. It’s a great skill to develop for any aspiring web developer or data engineer.
Power-Up Your Broken Link Checker: Customization Ideas
You’ve built a solid Broken Link Checker. But why stop there? Here are some ideas to make it even more powerful and personal:
- Recursive Checking: Our current script checks only one page. Can you modify it to crawl an entire website? You’d need to visit found links and check their links too! This involves managing visited URLs.
- Export to CSV/Excel: Instead of just printing, save the results to a file. A CSV or Excel file would be easier to share and manage. You could add columns for status code, link text, and the page where the link was found.
- Command-Line Arguments: Use Python’s
argparsemodule. This allows you to pass the target URL directly when running the script. No more editing the code every time! - Integrate with a Web Framework: Turn this script into a web application. You could use Flask or Django. Imagine a simple web interface where you paste a URL and get a report! Our Flask REST API Tutorial: Build a Simple Python Backend could be a great starting point for this.
- Handle JavaScript-rendered Links: Some websites load links using JavaScript. For these, you might need a headless browser like Selenium. This allows you to simulate a real browser visit. It’s a more advanced topic but very powerful. Learn more about HTTP Status Codes on MDN.
Go Forth and Validate!
You did it! You’ve successfully built a working Python script for a Broken Link Checker. This is a genuinely useful tool for anyone with a website. It shows your growing skills in Python, web requests, and HTML parsing. You’re now equipped to maintain healthier websites!
Take this project, customize it, and make it your own. Share your improvements with the procoder09.com community. What other cool things will you build? The world of web development is truly exciting!
broken_link_checker.py
# Python script for checking broken links on a given URL
# This script crawls a single web page, extracts all unique links, and checks their HTTP status codes.
# To run this script, you need to install the following libraries:
# pip install requests beautifulsoup4
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
import sys
import time
def get_all_links(url):
"""
Fetches the HTML content of a given URL and extracts all unique links.
Converts relative links to absolute links. Filters out non-HTTP(S) links.
"""
print(f"Fetching links from: {url}")
links = set() # Use a set to store unique links to avoid duplicates
try:
# Set a user-agent to mimic a browser, which can help avoid some blocks
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
response = requests.get(url, timeout=10, headers=headers) # 10-second timeout
response.raise_for_status() # Raise an HTTPError for bad responses (4xx or 5xx)
soup = BeautifulSoup(response.text, 'html.parser')
for anchor in soup.find_all('a', href=True):
href = anchor['href']
# Resolve relative URLs to absolute URLs
absolute_url = urljoin(url, href)
# Basic filtering for mailto, javascript, tel, etc., and ensure it's HTTP/HTTPS
if absolute_url.startswith(('http://', 'https://')) and not any(absolute_url.startswith(f) for f in ['mailto:', 'javascript:', 'tel:']):
# Filter out fragment identifiers (#) to avoid checking the same page multiple times
# and ensure we're checking a unique resource path/query
parsed_url = urlparse(absolute_url)
clean_url = parsed_url.scheme + "://" + parsed_url.netloc + parsed_url.path
if parsed_url.query:
clean_url += "?" + parsed_url.query
links.add(clean_url)
except requests.exceptions.Timeout:
print(f"[ERROR] Timeout fetching {url}")
except requests.exceptions.TooManyRedirects:
print(f"[ERROR] Too many redirects for {url}")
except requests.exceptions.ConnectionError:
print(f"[ERROR] Connection error for {url}")
except requests.exceptions.HTTPError as e:
print(f"[ERROR] HTTP error {e.response.status_code} for {url}")
except requests.exceptions.RequestException as e:
print(f"[ERROR] An unexpected request error occurred for {url}: {e}")
except Exception as e:
print(f"[ERROR] An unexpected error occurred while parsing {url}: {e}")
print(f"Found {len(links)} unique links to check.")
return sorted(list(links)) # Return a sorted list for consistent output
def check_link(link):
"""
Checks the HTTP status code of a given link.
Returns a tuple: (status_code, error_message)
"""
try:
# Using HEAD request is generally faster as it doesn't download the full content.
# However, some servers might not support HEAD or return incorrect status codes.
# For broader compatibility and accurate status for all methods, a GET request is safer.
# We use GET with allow_redirects=True to follow redirects and get the final status.
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
response = requests.get(link, timeout=10, allow_redirects=True, headers=headers) # 10-second timeout
response.raise_for_status() # Raise HTTPError for bad responses (4xx or 5xx)
return response.status_code, None
except requests.exceptions.Timeout:
return None, "Timeout"
except requests.exceptions.TooManyRedirects:
return None, "Too many redirects"
except requests.exceptions.ConnectionError:
return None, "Connection Error"
except requests.exceptions.HTTPError as e:
# If it's an HTTP error (4xx/5xx), we still return the status code
return e.response.status_code, f"HTTP Error {e.response.status_code}"
except requests.exceptions.RequestException as e:
return None, f"Request Error: {e}"
except Exception as e:
return None, f"An unexpected error: {e}"
def main():
if len(sys.argv) < 2:
print("Usage: python broken_link_checker.py <URL>")
print("Example: python broken_link_checker.py https://www.example.com")
sys.exit(1)
target_url = sys.argv[1]
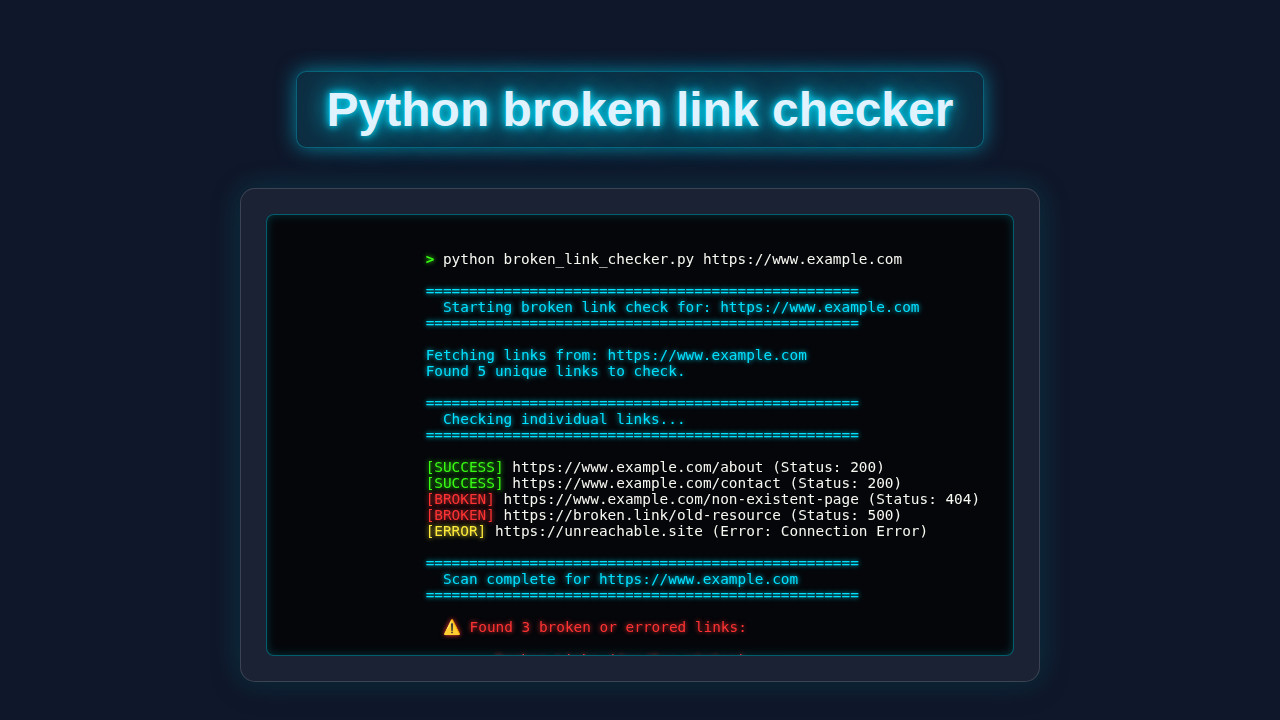
print(f"\n{'='*50}")
print(f"\n Starting broken link check for: {target_url}")
print(f"\n{'='*50}\n")
links_to_check = get_all_links(target_url)
broken_links_found = []
errored_links_found = []
if not links_to_check:
print("No links found on the page or an error occurred during link extraction. Exiting.")
sys.exit(0)
print(f"\n{'='*50}")
print(" Checking individual links...")
print(f"{'='*50}\n")
for i, link in enumerate(links_to_check):
# Print progress indicator on the same line
print(f"[{i+1}/{len(links_to_check)}] Checking: {link}", end='\r')
sys.stdout.flush() # Ensure the output is immediately written to console
status_code, error_message = check_link(link)
# Clear the progress line before printing the result
print(" " * (len(f"[{i+1}/{len(links_to_check)}] Checking: {link}") + 10), end='\r')
sys.stdout.flush()
if status_code and 200 <= status_code < 400:
# print(f"[SUCCESS] {link} (Status: {status_code})") # Uncomment to see successful links
pass # No need to print successful links unless specified
elif status_code:
print(f"[BROKEN] {link} (Status: {status_code})")
broken_links_found.append((link, status_code))
else:
print(f"[ERROR] {link} (Error: {error_message})")
errored_links_found.append((link, error_message))
time.sleep(0.05) # Small delay to be polite to servers and avoid being blocked
print(f"\n{'='*50}")
print(f"\n Scan complete for {target_url}")
print(f"\n{'='*50}\n")
total_broken_or_errored = len(broken_links_found) + len(errored_links_found)
if total_broken_or_errored == 0:
print(" 🎉 Congratulations! No broken or errored links found.\n")
else:
print(f" ⚠️ Found {total_broken_or_errored} broken or errored links:\n")
if broken_links_found:
print(" --- Broken Links (4xx/5xx status) ---")
for link, status in broken_links_found:
print(f" - {link} (Status: {status})")
if errored_links_found:
print("\n --- Errored Links (Network/Other) ---")
for link, error in errored_links_found:
print(f" - {link} (Error: {error})")
print("\n")
if __name__ == "__main__":
main()